
技术面的ai宝贝计划(总篇)
前言
传统的面试题整理+检索对 fakeable 的突破有限,且面试过程中鼠标翻找笔记或者键盘在搜索引擎敲字实在观感有点差。
2023起 AI 时代下面试 fakeable 的边界或者进一步说个人能力重心,我认为发生了比较大的变化,后续会单开一篇说说自己的想法。
先叠个甲,通过这个方式获取的 offer 是不会真去的。而作为面试官,我的理念是只要我的问题能被及时地、正确地、有条理地回答,至于候选人采用了什么其他辅助手段,我并不在乎。我也会周期性地评估我的面试题是否能适应新的环境。
技术架构
项目取名 rob_b_hood(宝贝计划)
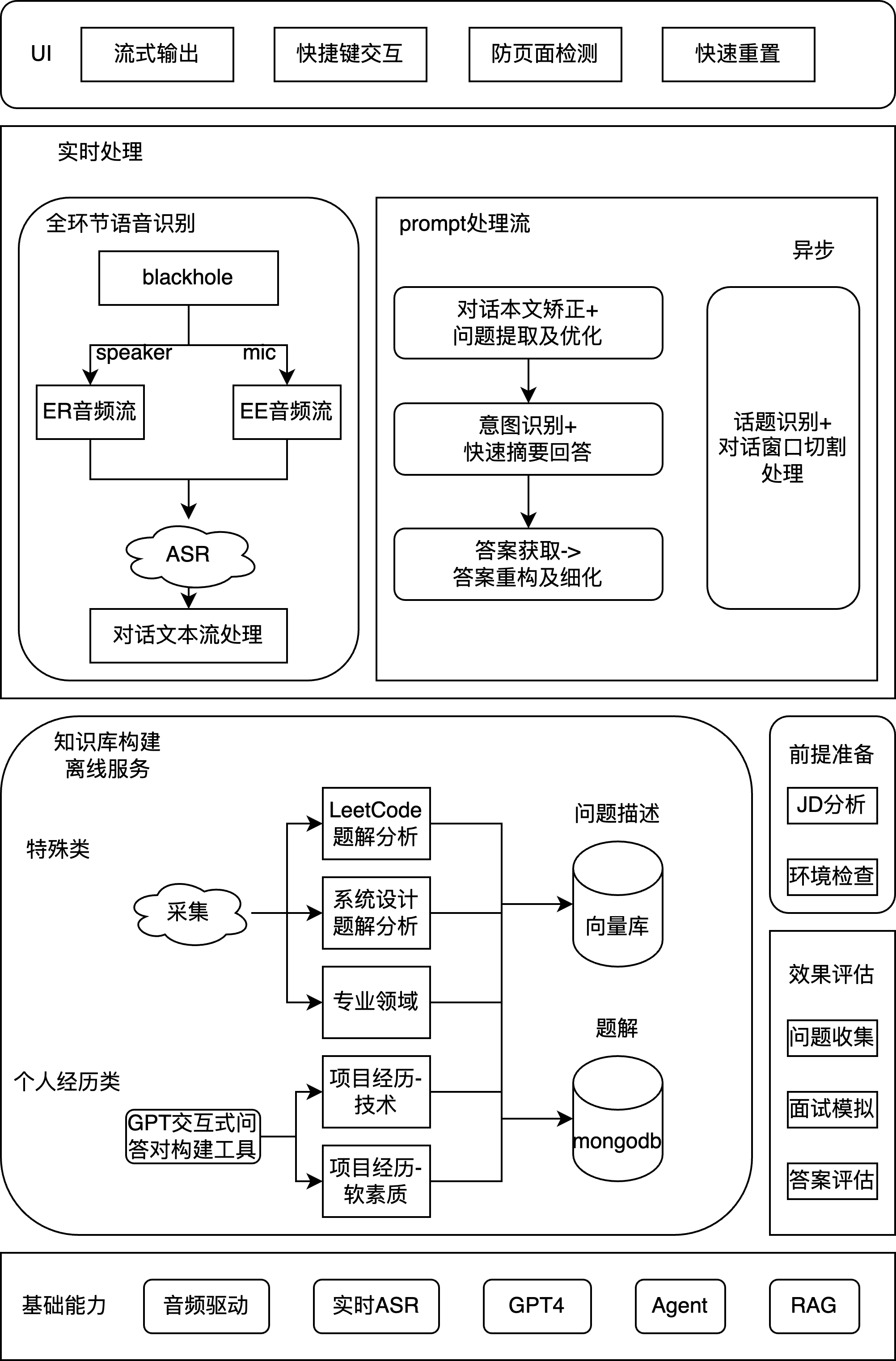
实时处理
音频接出
blackhole 虚拟音频驱动,可以在保持原音频流的同时,将 speaker(面试官)或 mic(候选人)的音频流同步转出至 ASR 模块
ASR模块
选型阿里云的通义千悟,通过 Go SDK 接入。支持传入实时音频流,在尾端 300ms 内返回文字流。P.S. 曾经尝试过 whisper 但时延和准确率达不到要求,特别是 whisper 对口音和中英夹杂的识别效果较差
Prompt 处理流
LLM 均选用了 GPT-4,针对不同类型的面试题会有不同的执行流程和 prompt 模板,以下给出的是最简单的处理流程。
Step1. 对话文本矫正以及问题识别
你是一位面试助手,在面试过程中需要时刻关注面试官的最新问题。面试对话记录的最后一条发言是面试官的最新发言,你的任务是提取并优化面试官的最新提问,具体要求如下:
1. 判断面试官的最新发言是否为一个提问,如果最新发言不是提问,则输出"null"。
2. 如果是提问,则从中提取出最新问题,并进行优化:
- 修正语言错误、错别字等
- 改写模棱两可或表达不清晰的问题
- 特别注意,部分先前对话中的关键信息点是最新问题的重要上下文,需合理地融入到最新问题中
3. 输出优化后的最新问题。
请直接输出优化后的最新问题或"null",不需要输出任何思考过程。
面试对话记录如下:
<conversation>
</conversation>
Step2. 快速回答 + 意图识别
P.S. 这一步是为了让候选人快速有个摘要回答,讲清楚全局思路
## 面试题
<question>
</question>
## 当前任务
请根据面试问题,简洁地列出3-5个回答意图。对于具体的技术问题,请聚焦于解释特定的技术概念或用途;对于开放性问题,请提出不同的解决方案或思考角度。确保每个意图的描述不超过两句话,直接相关于问题的主题。
注意:只需要列出回答意图,无需重复问题或提供其他额外信息。
Step2. 答案获取
面试题:
回答指导:
1. 简明扼要地回答问题的核心,确保回答准确无误。
2. 详细解释相关的技术概念,包括原理、应用和优缺点等。
3. 举例说明,提供实际应用场景来增强解释的清晰度。
4. 如有争议或不同观点,简要说明并提出自己的见解。
请根据上述指导,正式回答技术面试问题。
Step3. 答案重构
面试题:
已有回答部分:
请根据上述部分回答,进一步详细解释或展开相关的技术细节和应用场景。确保补充的信息具体、实用,并与原回答部分紧密相关。
Background Step
## 处理案例
<example>
对话记录:
[00:00] 面试官:让我们先谈谈你对MySQL的了解吧。
[00:10] 候选人:我对MySQL有一定的了解,它是一种关系型数据库管理系统。
[00:20] 面试官:你使用过哪些MySQL的优化技巧?
[00:30] 候选人:我使用过索引优化和查询优化来提高查询效率。
[00:40] 面试官:那么,在缓存方面你有什么经验吗?
[00:50] 候选人:是的,我有使用Redis作为缓存数据库的经验。
[01:00] 面试官:你能举个例子说明你是如何使用Redis的吗?
[01:05] 候选人:<触发快捷键>我曾经在电商项目中…
预期输出:{"new_topic_ts": 40}
</example>
## 待处理对话记录
<conversation>
</conversation>
## 当前任务
这是一段技术面试的对话记录。根据对话记录,确定新话题的开始时间,并以JSON格式输出该时间坐标。
注意:候选人通过`<触发快捷键>`来标记新话题的开始,你可以将快捷键的位置作为辅助参考,但候选人通常会在理解到新话题之后才按下快捷键,因此存在时间上的滞后。
离线知识库构建
在现在越来越卷的时代,如果直接用 LLM 回答问题,大概率离挂就不远了。LLM 在回答的深度以及正确率上堪忧。
以下对面试题类型进行分析,对不同类型的面试题采用了不同的处理方式。这里主要阐述思路,后续会逐渐公开实现细节。
- 专业知识 - 包括计算机网络、操作系统、语言特性、框架特性、设计模式、数据库、中间件、自动化测试、DevOps、安全
- LeetCode
- SQL
- 系统设计
- 专业领域 - 对我而言,包括 AIGC、爬虫、风控、后端
LeetCode
这是最好处理的题型。
Step1. 爬取获取 LeetCode 所有题目,包括问题描述、标签和题解
Step2. prompt 分析、挑选、解释题解并存储。P.S. 这一步是为了删除不满足要求的题解,同时帮助你回答算法题时能讲清楚思路,能回答出基本的 follow-up
Step3. 构建索引
前两个步骤可参考我的开源项目:gpt_algo
SQL
对于我而言,SQL 题出现的机会较少,我选择让 LLM 直接处理
系统设计
系统设计题比较有限
Step1. 收集常见的系统设计题和答案
Step2. 人工逐个理解题目和答案,针对不明白的地方,和 LLM 交互问答加强答案
Step3. 将整体方案,问答对存储到向量库
后续我会逐步更新我整理的题目和答案,并给出与 LLM 协同补充细节的过程
专业知识
Step1. 爬取面经,主要来自脉脉、牛客、搜索引擎的博客
Step2. 通过 prompt 解析出面经中的职位、公司和具体问题
Step2. 通过 prompt 流 + 检索,引导 llm 给出比较完善的回答
step3. 存储问答对至向量库
专业领域
专业领域方面,高质量的内容渠道少,散落在各个博客、公众号和知识星球中。
主要来自自己平时的整理,处理思路是先整理出这个专业领域的大框架,细节通过爬虫 + LLM 补充。人工 review 整理至 notion,导出至知识库。
项目经历
这真得靠自己了。
不过我还是设计了一个给出简历信息,LLM 针对简历中的项目介绍进行不断提问、追问的 prompt 流程,辅助梳理项目经历